

Model Stacking을 통한 Ensemble 방법
데이터분석을 하면서 흔하게 겪는 문제는 바로 overfitting이다. 충분히 많은 데이터가 있고 sampling / 데이터 분포도의 변동이 없다면 문제가 없겠지만, 사실 이런 경우는 흔치 않다.
Overfitting을 방지하기 위해 regularization, dropout, domain adaption 등 여러 연구가 선행되어 왔다. 지난 번에 알아본 Model Averaging에 이어 이번 글에서는 Stacking Ensemble에 대해 알아본다.
model averaging
model averaging의 장점은 예측 결과에 대한 편차를 줄여줌으로써 overfitting을 감소시키는 효과가 있다는 것이다. 하지만 sub-model의 정확도와 무관하게 최종 prediction에 각 sub-model이 동등하게 사용된다. (classification이라면 최빈값이, regression이라면 평균값)
weighted averaging model
이를 개선하기 위해 등장한 것이 weighted averaging model이다. model averaging처럼 각 sub-model의 결과값을 결합하여 최종 output을 내지만, 각 sub-model의 기여도가 동등한 것이 아니라 weight 값에 따라 다르게 부여된다.
stacked generalization
weighted averaging model을 조금 더 일반화해서 각 sub-model의 예측결과를 결합하는 과정을 linear weighted sum으로 대체하는 방법이다. sub-model의 각 예측결과는 linear regression 모델의 train data로 사용될 수 있다. 이러한 방식을 stacked generalization, stacking이라고 한다.
Stacking
Stacking procedure는 다음과 같이 2 단계로 진행된다.
- Level 0 : training dataset을 이용하여 sub-model 예측 결과를 생성한다.
- Level 1 : level 0의 output 결과가 level 1의 input 값이 된다. level 0의 output을 training data로 사용하여 meta learner 모델을 생성한다.
이러한 2 단계 과정을 거치며 stacked generalization(meata learner)은 level 0에서 사용한 training data와 다른 dataset을 사용하기 때문에 overfitting을 방지하고 bias를 줄이게 된다.
Stacked generalization 과정에서 level 0 모델들은 되도록 다양한 예측 결과를 meta learner에서 input 값으로 활용할 수 있도록 각기 다른 알고리즘을 사용하는 것이 좋다.
Combination sub-models
- 각 sub-model의 결과를 결합하는 meta learner 모델은 simple linear model을 사용하는 것이 일반적이다.
- 또는 sub-model을 neural network으로 생성하고 meta learner를 big neural network model로 설정하여 sub-model을 embedding 시키는 방법도 있다
Combination predictions
- regression의 경우 각 sub-model의 값이 그대로 meta-learner의 input 값으로 들어가게 된다.
- classification 경우라도 각 sub-model의 예측 결과는 label 보다는 label probabilities를 input 값으로 넣는다. 이것이 더 좋은 결과를 생성한다.
아래 다중 클래스 분류 문제를 통해 ensemble stacking을 학습해보자
Multi-Class Classification Problem
scikit-learn의 make_blobs() function을 사용하여 3 class label을 가진 x, y 좌표 데이터를 생성한다. 이 데이터들의 standard deviation은 (의도적으로 2.0)으로 셋팅한다. 이는 “good enough” 정답 후보가 많아서 high variance한 model을 만들기 위해서이다.
생성된 dataset은 크기가 작기 때문에 holdout 방식으로 training한다. 1100개의 dataset을 생성하고 그 중 100개는 training, 1000개는 test dataset으로 사용한다.
25개의 hidden layer과 3개의 output layer(3 label classification 문제이므로)를 가진 모델을 설정하고 500 epoch, validation set으로 test dataset을 사용한다.
# develop an mlp for blobs dataset
from sklearn.datasets.samples_generator import make_blobs
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense
from matplotlib import pyplot
import warnings
warnings.filterwarnings('ignore')
# generate 2d classification dataset
X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2)
# one hot encode output variable
y = to_categorical(y)
# split into train and test
n_train = 100
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
print(trainX.shape, testX.shape)
# define model
model = Sequential()
model.add(Dense(25, input_dim=2, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=500, verbose=0)
(100, 2) (1000, 2)
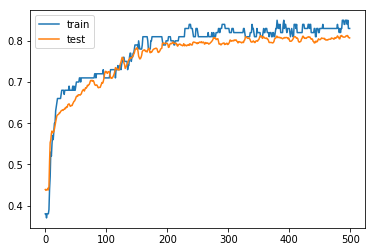
Training, test data accuracy를 그려보면 다음과 같다
Train : 0.84, Test : 0.81
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# learning curves of model accuracy
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show()
Train: 0.830, Test: 0.807
Train and Save Sub-Models
이번에는 단일 모델이 아니라 여러개의 sub-model을 구성하는 방법이다. Level 0 단계로 위와 같은 모델을 sub-model로 구성하고, Level 1 단계로 ensemble의 meta-learner로 holdout dataset을 사용한다.
이는 예제를 간단하게 구성하기 위함이고, 더욱 좋은 결과를 내기 위해서는 sub-model을 각 다른 알고리즘으로(deeper, wider…) 대체하고 meta-learner에서는 holdout 대신 k-fold cross-validation을 사용하는 것이 좋다.
위와 같이 25 hidden (relu) layer / 3 output layer 모델을 sub-model로서 5개 생성하고 “models/” 폴더 밑에 저장한다.
# example of saving sub-models for later use in a stacking ensemble
from sklearn.datasets.samples_generator import make_blobs
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense
from matplotlib import pyplot
from os import makedirs
# fit model on dataset
def fit_model(trainX, trainy):
# define model
model = Sequential()
model.add(Dense(25, input_dim=2, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
model.fit(trainX, trainy, epochs=500, verbose=0)
return model
# generate 2d classification dataset
X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2)
# one hot encode output variable
y = to_categorical(y)
# split into train and test
n_train = 100
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
print(trainX.shape, testX.shape)
# create directory for models
#makedirs('models')
# fit and save models
n_members = 5
for i in range(n_members):
# fit model
model = fit_model(trainX, trainy)
# save model
filename = 'models/model_' + str(i + 1) + '.h5'
model.save(filename)
print('>Saved %s' % filename)
(100, 2) (1000, 2)
>Saved models/model_1.h5
>Saved models/model_2.h5
>Saved models/model_3.h5
>Saved models/model_4.h5
>Saved models/model_5.h5
Separate Stacking Model
이제는 위에 저장한 5개의 sub-model을 사용하여 meta-learner을 train한다.
# stacked generalization with linear meta model on blobs dataset
from sklearn.datasets.samples_generator import make_blobs
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from keras.models import load_model
from keras.utils import to_categorical
from numpy import dstack
앞서 저장한 n_models(5개)의 sub-model을 loading하는 함수
# load models from file
def load_all_models(n_models):
all_models = list()
for i in range(n_models):
# define filename for this ensemble
filename = 'models/model_' + str(i + 1) + '.h5'
# load model from file
model = load_model(filename)
# add to list of members
all_models.append(model)
print('>loaded %s' % filename)
return all_models
stacked_dataset() function
- members : sub-model list
- inputX : test data
inputX에 대해 sub-model을 prediction 하고 각 sub-model 예측 결과를 dstack을 사용하여 하나의 dataset으로 생성한다.
각 sub-model의 예측 결과는 (1000, 3)의 shape를 가지고 있다. (1000개의 test dataset, 3 class probability)
5개 sub-model에 대해 각 예측 결과를 dstack하면 (1000, 3, 5) shape을 가지게 된다. 이를 meta learner의 training dataset으로 사용하기 위해 (1000, 3*5) 모양으로 reshape한다.
# create stacked model input dataset as outputs from the ensemble
def stacked_dataset(members, inputX):
stackX = None
for model in members:
# make prediction
yhat = model.predict(inputX, verbose=0)
# stack predictions into [rows, members, probabilities]
if stackX is None:
stackX = yhat
else:
stackX = dstack((stackX, yhat))
# flatten predictions to [rows, members x probabilities]
stackX = stackX.reshape((stackX.shape[0], stackX.shape[1]*stackX.shape[2]))
return stackX
sub-model의 예측 결과가 dstack / reshape를 사용하여 meta-learner를 위한 training dataset으로 변환된다. 얻어진 training dataset을 이용하여 LogisticRegression() 모델을 생성한다.
참고.
Logistic regression은 binary classification만 제공하지만, LogisticRegression은 multi-class classification을 제공한다.
# fit a model based on the outputs from the ensemble members
def fit_stacked_model(members, inputX, inputy):
# create dataset using ensemble
stackedX = stacked_dataset(members, inputX)
# fit standalone model
model = LogisticRegression()
model.fit(stackedX, inputy)
return model
stacked_prediction()
meta-learner에서 사용하는 prediction 함수
sub-model의 예측결과를 모아서 stackedX로 결합한 뒤 meta learner의 training data로 사용한다.
# make a prediction with the stacked model
def stacked_prediction(members, model, inputX):
# create dataset using ensemble
stackedX = stacked_dataset(members, inputX)
# make a prediction
yhat = model.predict(stackedX)
return yhat
# generate 2d classification dataset
X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2)
# split into train and test
n_train = 100
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
print(trainX.shape, testX.shape)
# load all models
n_members = 5
members = load_all_models(n_members)
print('Loaded %d models' % len(members))
# evaluate standalone models on test dataset
for model in members:
testy_enc = to_categorical(testy)
_, acc = model.evaluate(testX, testy_enc, verbose=0)
print('Model Accuracy: %.3f' % acc)
(100, 2) (1000, 2)
>loaded models/model_1.h5
>loaded models/model_2.h5
>loaded models/model_3.h5
>loaded models/model_4.h5
>loaded models/model_5.h5
Loaded 5 models
Model Accuracy: 0.811
Model Accuracy: 0.808
Model Accuracy: 0.812
Model Accuracy: 0.816
Model Accuracy: 0.810
# fit stacked model using the ensemble
model = fit_stacked_model(members, testX, testy)
# evaluate model on test set
yhat = stacked_prediction(members, model, testX)
acc = accuracy_score(testy, yhat)
print('Stacked Test Accuracy: %.3f' % acc)
Stacked Test Accuracy: 0.828
Signle model을 사용한 경우 0.81 정확도가 나왔고, 해당 single model과 같은 모델을 sub-model로 5개 만들고 meta-learner을 LogisticRegression만으로 돌려도 0.828로 정확도가 높아지는 것을 확인할 수 있다
Integrated Stacking Model
이번엔 sub-model을 neural network로 구성할 경우 keras functional interface를 사용하여 meta-learner에 embedding 시키는 방법이다.
이 경우 장점은 submodel의 output이 직접 meta-learner의 input으로 전달된다는 것이다. 또한 추가적으로 meta-learner와 상호작용하여 submodel들의 weight를 업데이트 할 수 있다.
요구사항은 처음 meta-learner가 training 될 때에는 각 sub-model의 weight가 not trainable로 셋팅되어 update되지 않아야 한다는 것이다. 또한 Keras에서는 각 layer가 unique한 이름을 가져서 loading된 sub model 중 어느 layer가 update 될 것인지 명확하게 하는 것이다.
# stacked generalization with neural net meta model on blobs dataset
from sklearn.datasets.samples_generator import make_blobs
from sklearn.metrics import accuracy_score
from keras.models import load_model
from keras.utils import to_categorical
from keras.utils import plot_model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers.merge import concatenate
from numpy import argmax
sub-model 로딩
# load models from file
def load_all_models(n_models):
all_models = list()
for i in range(n_models):
# define filename for this ensemble
filename = 'models/model_' + str(i+1) + '.h5'
# load model from file
model = load_model(filename)
# add to list of members
all_models.append(model)
print('>loaded %s' % filename)
return all_models
define_stacked_model
sub-model을 list로 가져와서 각 모델의 layer를 “not trainable”하고 unuque한 이름을 가진 개체로 셋팅한다.
각 sub-model의 input을 meta-learner의 multi-headed input으로, 각 sub-model의 output을 meta-learner의 output으로 지정하고 concatenate로 합친다.
# define stacked model from multiple member input models
def define_stacked_model(members):
# update all layers in all models to not be trainable
for i in range(len(members)):
model = members[i]
for layer in model.layers:
# make not trainable
layer.trainable = False
# rename to avoid 'unuque layer name' issue
layer.name = 'ensemble_' + str(i+1) + '_' + layer.name
# define multi-headed input
ensemble_visible = [model.input for model in members]
# concatenate merge output from each model
ensemble_outputs = [model.input for model in members]
merge = concatenate(ensemble_outputs)
hidden = Dense(10, activation = 'relu')(merge)
output = Dense(3, activation = 'softmax')(hidden)
model = Model(inputs=ensemble_visible, outputs=output)
# plot graph of ensemble
plot_model(model, show_shapes=True, to_file='model_graph.png')
# compile
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
Ensemble Model Network Graph

위에서 sub-model들이 not trainable로 명시되었기 때문에 training 중 sub-model의 weight는 업데이트 되지 않는다. fit_stacked_model()에서는 300 epoch 동안 neural network 모델을 training 한다.
# fit a stacked model
def fit_stacked_model(model, inputX, inputy):
# prepare input data
X = [inputX for _ in range(len(model.input))]
# encode output data
inputy_enc = to_categorical(inputy)
# fir model
model.fit(X, inputy_enc, epochs=300, verbose=0)
# make a prediction with a stacked model
def predict_stacked_model(model, inputX):
# prepare input data
X = [inputX for _ in range(len(model.input))]
# make prediction
return model.predict(X, verbose=0)
기존 모델링 방법과 같이 train/test datase 준비
# generate 2d classification dataset
X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2)
# split into train and test
n_train = 100
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
print(trainX.shape, testX.shape)
(100, 2) (1000, 2)
기존에 훈련된 5개의 sub-model을 로딩하고 model network를 정의한다
# load all models
n_members = 5
members = load_all_models(n_members)
print('Loaded %d models' % len(members))
# define ensemble model
stacked_model = define_stacked_model(members)
# fit stacked model on test dataset
fit_stacked_model(stacked_model, testX, testy)
>loaded models/model_1.h5
>loaded models/model_2.h5
>loaded models/model_3.h5
>loaded models/model_4.h5
>loaded models/model_5.h5
Loaded 5 models
기존 sub-model의 output을 input값으로 받아들여 훈련된 stacked_model을 가지고 예측 수행, argmax로 y값을 변환시켜준다
# make predictions and evaluate
yhat = predict_stacked_model(stacked_model, testX)
yhat = argmax(yhat, axis = 1)
acc = accuracy_score(testy, yhat)
print('Stacked Test Accracy : %.3f' % acc)
Stacked Test Accracy : 0.837
neural network로 stacking ensemble 구현한 모델의 최종 accuracy는 0.837로 LogisticRegression으로 stacking ensemble을 구현한 accuracy : 0.828 보다 더 좋은 결과를 가져왔다.
이와 같이 stacking ensemble은 single 모델보다 더 높은 정확도를 가져오지만 많은 시간이 소요되고, computation cost가 높기 때문에 실무보다는 Kaggle 같은 경연대회에서 많이 쓰이는 추세이다.
Related Posts
- https://inspiringpeople.github.io/data%20analysis/Ensemble_Keras/
Reference
- https://machinelearningmastery.com/stacking-ensemble-for-deep-learning-neural-networks/#comment-472105
댓글남기기