

Paragram Word Embedding
Kaggle Toxic 2nd Competition을 둘러보다가 “Paragram Word Embedding”이라는 새로운 word embedding을 발견하여 이를 소개한다.
Paragram Word Embedding이란 PPDB라는 데이터베이스 기반으로 만들어지는 의역기반 word embedding이다.
[PPDB]
논문 : PPDB: The Paraphrase Database
사이트 : PPDB
PPDB는 16 개 언어로 수백만 개의 구를 포함하는 자동 추출 데이터베이스이다. 우리가 경험적으로 신뢰하고 있는 어구 쌍 목록으로 단어들로 구성되어 있다. (Creative Commons Attribution 3.0 United States 라이선스에 따라 무료로 사용 가능)
해당 사이트에 가서 papa라는 단어를 실험해보니 dad, daddy, pa, dad, pap 등 papa에 해당하는 여러 variation 단어들이 나온다.
[Paragram Word Embedding]
논문 : From Paraphrase Database to Compositional Paraphrase Model and Back
[개요]
PPDB의 유용성에도 불구하고 완전한 적용범위와 최적의 사용방법이 명확하지 않다. 따라서 PPDB의 phrase 쌍을 활용하여 PPDB의 내부 스코어보다 더 정확하게 의역을 하고 적용 범위를 개선하는 parametric 모델을 만들어 낸다.
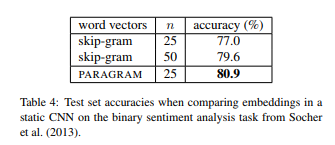
논문에서 소개한 결과에 따르면 Paragram Word Embedding을 사용해서 Sentiment Analysis를 적용했을 때 (Kim yoon, CNN 방식) 기존 skip-gram word2vec 모델보다 아래와 같이 정확도 향상이 되었다고 명시되어 있다.
[활용]
gensim에서는 paragram을 지원하지 않으므로 다음과 같이 사용한다
paragram_model={}
for line in open('paragram_300_sl999.txt', encoding="utf8", errors='ignore'):
if len(line)>100:
try:
if line.split(' ')[0] in words:
paragram_model[line.split(' ')[0]]=np.array(line.split(' ')[1:], dtype = np.float32)
except: continue
자동 추출 데이터베이스를 기반으로 만들어지는 word embedding 모델이고, 또한 의역이 포함되어 있어 굉장히 유용할 것이라고 생각된다. 기존에 NLP 처리를 할 때 같은 의미를 가지는 여러단어들에 대한 처리를 할 때 domain database를 따로 만들거나, 직접 전처리 해줘야하는 어려움이 있었는데, 이러한 word embedding을 사용하면 huristic하게 알고 있는 단어에 대한 내용들이 포함되기 때문에 정확도가 많이 향상될 것으로 보인다. 사이트에서 확인해보면 총 8개국의 언어를 지원하는데, 아쉽게도 한글에 대한 지원은 아직 없다.
댓글남기기