

Text Mining - 1. 전체 개요
Text Mining에 입문한지 얼마되지 않았지만,
여기저기 삽질하고 구글링했던 노력을 잊지 않기 위해서 그 과정을 정리하려고 한다.
그 어떤 데이터보다도 Text Data는 다루기 어렵고 (특히, 한글 ㅠ) 깨끗한 데이터로 만들기까지 공이 많이 들어간다. 그럼에도 불구하고, 여전히 만족할만한 clean data가 아닌 개선 포인트 투성이의 아쉬운 data이다. Text Mining이라는 것은 실력과 기술로 쌓아올린다기보다는 노가다와 삽질을 얼마나 잘 견디냐에 따른 산출물처럼 느껴지기도 한다.
하지만 사람의 언어를 컴퓨터에게 이해시키는 것은 얼마나 매력적인것인가. 사람끼리도 쉽지 않은 일을, 아무렴… 어려울 수 밖에 없는 일을 하고 있구나, 하고 마음을 달래본다.
단어를 숫자로 번역하면 누구나 정확히 그 말을 이해할 수 있다.
목소리, 억양, 아, 어, 오 등 모든 발음이 사라지고 모든 오해가 해결되며 정확한 숫자로 생각을 표현한다. 모든 개념을 명확하게 표현하는 것이다.
– E.L. Doctorow, Billy Bathgate
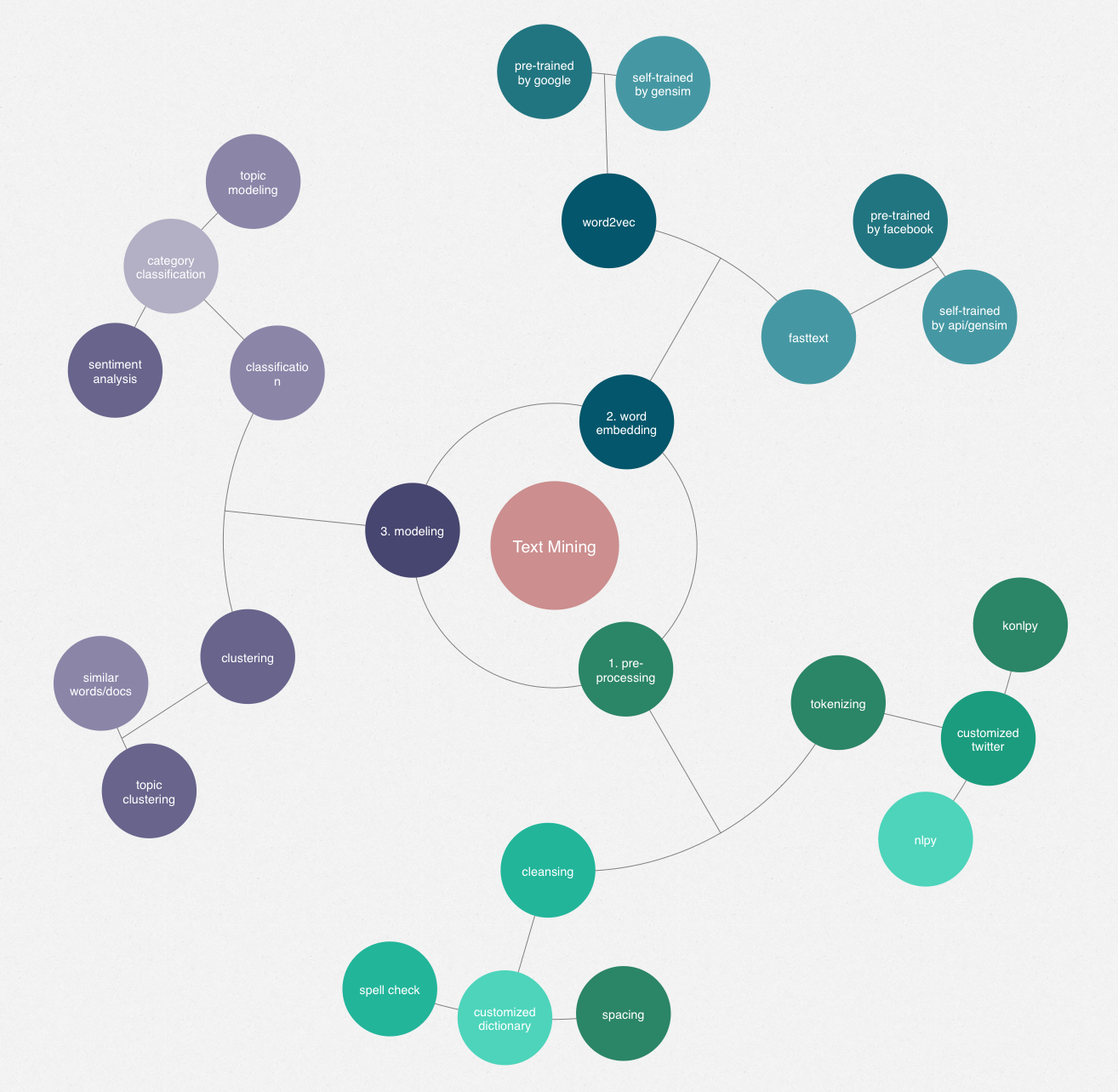
Text Mining 중 거쳐갔던 과정들을 마인드맵으로 그려보았다. 마인드맵으로 그리니… 한눈에… 복잡해 보인다;; 그러나 온라인 상에는 나와 같이 무지한 사람들을 위해 자료를 잘 정리해두신 많은 덕인들이 계셔 큰 도움을 받을 수 있었다. (그래서 나도 여기에 정리한다. ㅎㅎ)
관련 주제에 대해 정리한 내용과 참고했던 사이트 링크 등을 공유할 예정이다.
[Text Mining]
1. Pre-processing
-
cleansing / tokenizing
ckonlpy를 이용해서 Text Data cleansing 및 tokenizing 하기 : 링크 바로가기 -
영어 / 한글 Pre-processing 실습
2. Word Embedding
3. Modeling
- clustering
- classification
- LDA
댓글남기기