

Tonnetz 음악이론을 딥러닝에 접목시키기
Image recognition 분야는 대량의 데이터도 확보되어 있고 모델 정확도도 이미 사람의 수준을 넘어서고 있다. 반면 음악은 모델을 훈련하기 위한 데이터가 불충분하여 어려움이 있지만 오랜 역사 동안 음악가들이 구축해 놓은 탄탄한 음악 이론이 있다. 이를 딥러닝에 접목 시킨다면 더욱 개선된 모델을 만들 수 있지 않을까?하는 아이디어에서 출발한 논문을 소개한다.
논문 제목 : “Modeling Temporal Tonal Relations in Polyphonic Music through Deep Networks with a Novel Image-Based Representation” (AAAI2018)
논문 구현 : https://github.com/ChinghuaChuan/tonnetzDL
이 논문은 tonnetz라는 음악이론을 이용하여 음악을 2D graphic한 차원으로 변형시켜 딥러닝에 활용한다.
(1) tonnetz (by Euler)
1739년 오일러에 의해 처음 기술된 것으로 음악의 tonality와 tonal space의 관계를 graphical한 방식으로 표현한 것
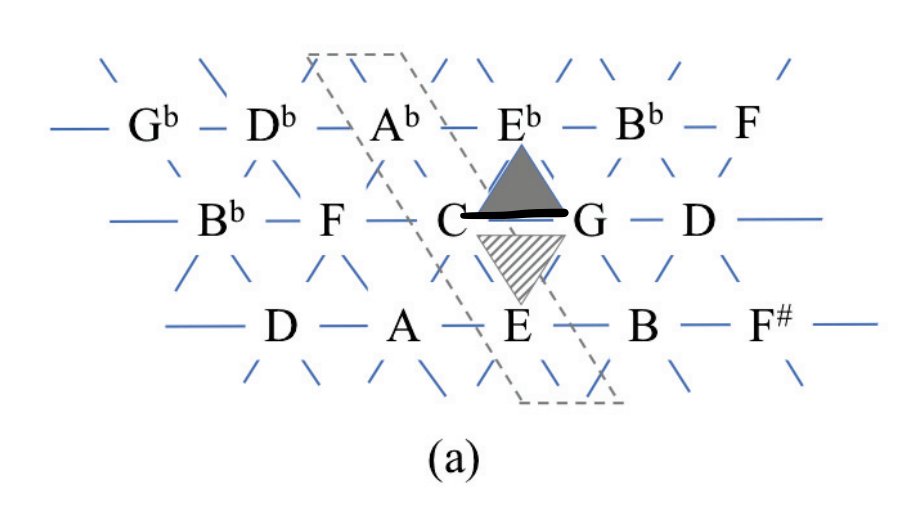
- 하나의 노드는 12 pitch들과 연결
- 오른쪽은 완전 5도, 왼쪽은 완전 4도
- 3개의 노드는 3도화음으로 세모 모양 구성 (위 세모는 minor, 아래 세모는 maj 코드)
이렇게 tonalty를 geographical 하게 표현하면 어떤 점이 좋을까? 바로 음악에 숨어 있는 패턴이라던가, 관계 등을 시각적으로 잘 확인할 수 있다는 것이다. 이해가 잘 되지 않는다면 아래 영상을 참고하자. Gymnopedie No.1 곡을 tonnetz로 표현한 것이다.
확실히 시각적으로 표현하니 음악 안에 녹아있던 패턴이나 반복들이 확인하기 쉬워진다. 이러한 domain knowledge를 2차원 matrix로 embedding하여 딥러닝에 반영하는 것이 이 논문의 아이디어이다.
그럼 tonnetz embedding, model architecture 순으로 자세히 알아보도록 하자.
(1) Data
- classical music from various composers
- MuseData dataset, midi format
- 524 training, 135 validation, 124 test sets
- Bach, Beethoven, Haydn, and Mozrt
(2) extended tonnetz embedding
본 논문에서는 오일러에 의한 tonnetz가 아닌 extended tonnetz가 사용되었다. 기존의 삼각형 패턴을 사각형으로 확장한 것인데, 미디 데이터를 임베딩 matrix로 바꾸기 위함으로 해석된다. 각 선들 (세로, 가로, 왼쪽, 오른쪽)은 기존의 tonnetz처럼 tonalty 특성을 반영한다.
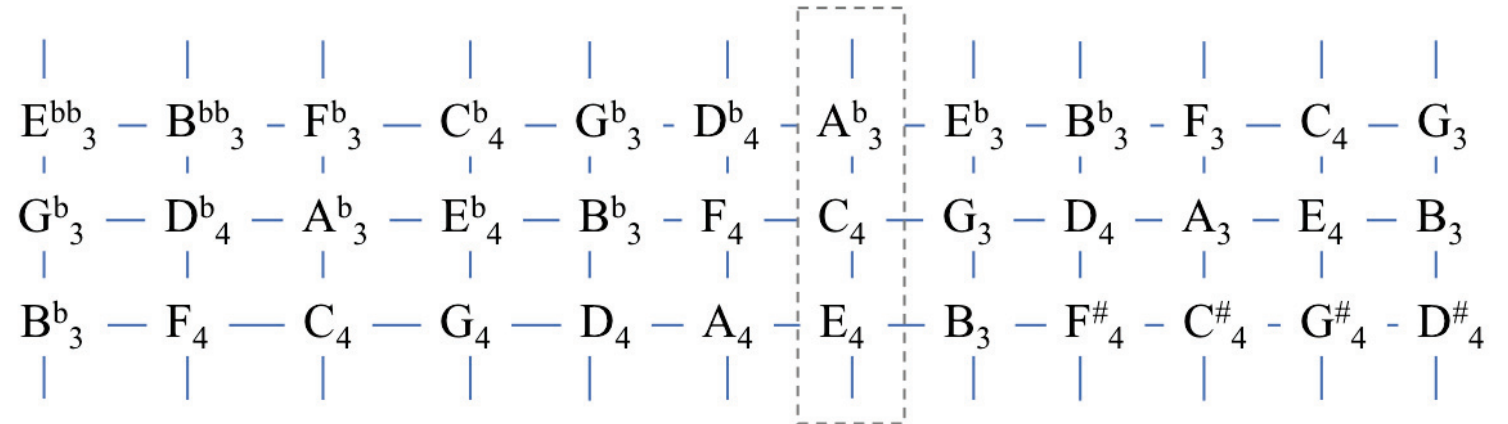
- 오른쪽과 완전 5도 관계
- C4 than G3 is closer to C4 than G4 (–> 이부분은 잘 이해가 되지 않는다)
- 세로축은 장3도 관계 (common tonnetz에서는 빗금선)
- 가로축은 데이터의 pitch range (여기서는 24 rows, C0 to C#8)
- polyphonic music에서 time slice 동안 여러 음정이 동시에 연주되는 것을 모델링 할 수 있게 함
(3) network architecture
딥러닝 모델은 2단계로 구성된다.
첫 번째는 two-layered convolutional autoencoder로 아래 그림 (a)와 같다.
- autoencoder의 input은 tonnetz matrix embedidng 값이 됨
- 처음 encoder 부분은 tonnetz의 abstract representation을 반영하고, decoder 부분에서는 input과 가장 근접한 값으로 디코딩된다.
- loss function은 encoding된 X와 decoding된 X’의 sigmoid cross entropy
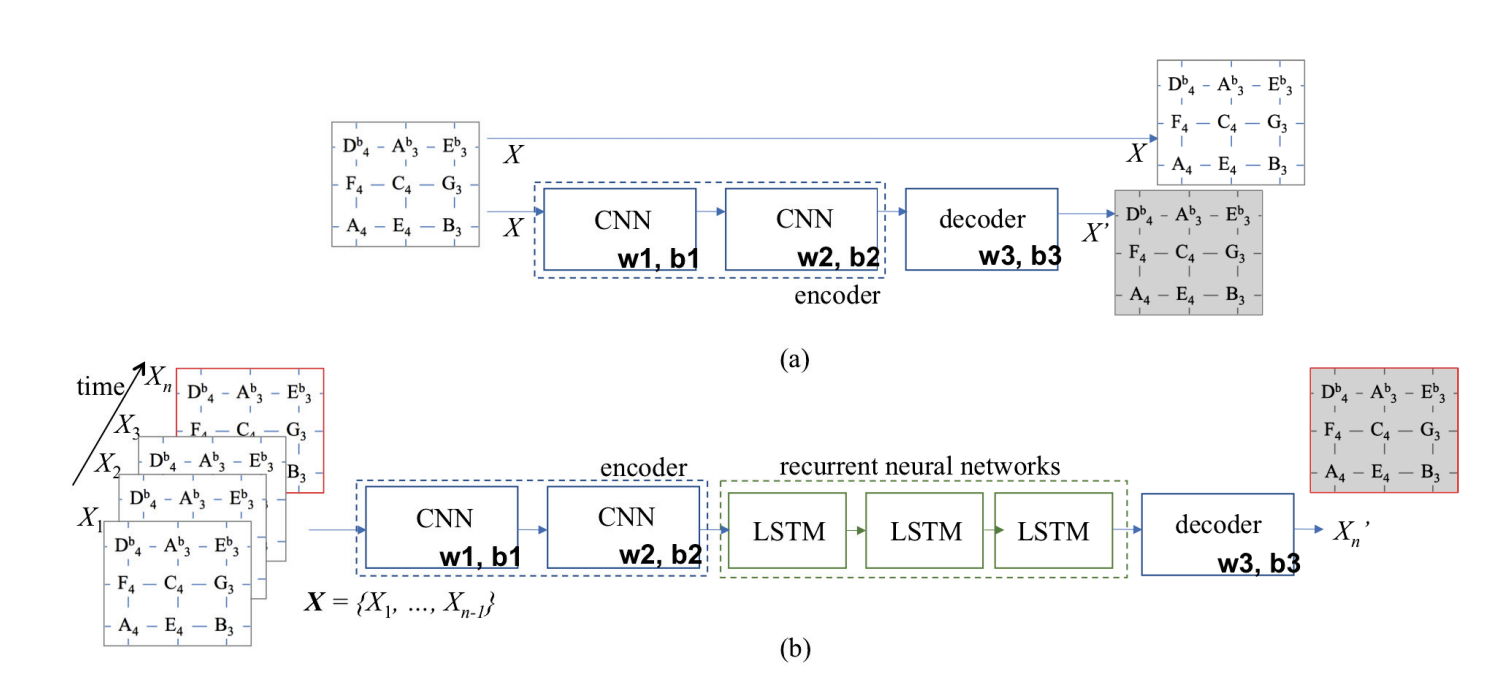
두 번째는 three-layered LSTM network이다.
- 앞의 CNN autoencoder의 output 값이 LSTM network의 입력 값으로 제공
- vanishing gradient problem 방지를 위해 LSTM (CEC, constant error carousel) 사용
- 3 hidden layer, sigmoid loss function
(4) 결과
- tonnetz embedding을 모델에 반영한 결과 기존보다 tonnaly stable, repeated patterns가 기존 모델보다 잘 반영됨
- tonally stable, repeated pattern 반영으로 인해 음악이 더욱 structured music으로 구성됨
모델링을 현업에서 진행하다보면, 정확도를 높이는 것보다 현업에서 오랫동안 일해오던 분들의 domain knowledge를 어떻게 모델에 반영할 수 있느냐가 key point인데, 그런면에서 music domain을 geographical한 2차원으로 표현해서 모델에 반영했다는 것이 굉장히 좋은 시도였다고 생각한다. 논문을 읽었지만 아직 해결하지 못한 궁금점이 있어 소스 코드도 추후에 확인해봐야겠다.
[궁금한 점]
- Midi file을 열어보니 여러개의 악기가 혼재되어 있는데 tonnetz를 어떤 방식으로 뽑았는지?
- tonnetz vocabulary 모델 생성 방법
- autoencoder CNN에서 tonnetz window-slicing 방식
댓글남기기