

Music21 라이브러리를 활용한 미디 데이터 분석
미디 데이터를 파이썬으로는 어떻게 확인해볼 수 있을까? 이미 파이썬에 여러 유용한 라이브러리들이 제공되고 있지만 그 중 Music21을 통해 전처리 및 시각화하는 방법을 알아본다.
Music21 라이브러리를 이용하면 곡의 음정과 코드를 쉽게 다룰 수 있다. 이 글은 아래 링크 글을 번역한 것으로 미디 데이터를 다루는 기초적인 내용도 좋았지만 음악 코드를 string 처럼 취급하여 자연어처리에서 자주 응용되는 Word2Vec을 응용했다는 점이 참신했다
참고 링크 : You can find a high-level description of it on this Medium article.
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Listing current data on our folder.
import os
print(os.listdir("."))
['midi-music-data-extraction-using-music21.ipynb', '.ipynb_checkpoints']
Opening MIDI files
이 글에서 사용되는 데이터셋은 Sonic 게임에 나오는 midi 음악 데이터셋이다. 원곡과 팬 및 여러 사람들이 편곡, cover한 곡이 함께 포함되어 있다. (변형된 곡은 원곡제목_숫자 형식으로 저장되어 있음) 먼저 큰 데이터를 다루가 전에 미디파일 하나만 예제로 불러와서 여러 작업을 해보자. 주제곡과도 같은 green-hill-zone.mid 파일을 로딩한다.
# Defining some constants and creating a new folder for MIDIs.
midi_path = "MIDIs"
sonic_folder = "sonic"
!rm -r $midi_path
!mkdir $midi_path
# Some helper methods.
def concat_path(path, child):
return path + "/" + child
def download_midi(midi_url, path):
!wget $midi_url --directory-prefix $path > download_midi.log
# Downloading an example file.
sonic_path = concat_path(midi_path, sonic_folder)
download_midi(
"https://files.khinsider.com/midifiles/genesis/sonic-the-hedgehog/green-hill-zone.mid",
sonic_path)
print(os.listdir(sonic_path))
rm: MIDIs: No such file or directory
--2019-08-25 17:57:48-- https://files.khinsider.com/midifiles/genesis/sonic-the-hedgehog/green-hill-zone.mid
Resolving files.khinsider.com (files.khinsider.com)... 45.56.66.21
Connecting to files.khinsider.com (files.khinsider.com)|45.56.66.21|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 13034 (13K) [audio/midi]
Saving to: ‘MIDIs/sonic/green-hill-zone.mid’
green-hill-zone.mid 100%[===================>] 12.73K --.-KB/s in 0.001s
2019-08-25 17:57:49 (14.4 MB/s) - ‘MIDIs/sonic/green-hill-zone.mid’ saved [13034/13034]
['green-hill-zone.mid']
Music21 Library를 통해서 쉽게 미디 파일을 열수 있다. Music21 Library에 대한 자세한 설명은 아래 링크에 가면 확인해 볼 수 있다. documentation file.
from music21 import converter, corpus, instrument, midi, note, chord, pitch
def open_midi(midi_path, remove_drums):
# There is an one-line method to read MIDIs
# but to remove the drums we need to manipulate some
# low level MIDI events.
mf = midi.MidiFile()
mf.open(midi_path)
mf.read()
mf.close()
if (remove_drums):
for i in range(len(mf.tracks)):
mf.tracks[i].events = [ev for ev in mf.tracks[i].events if ev.channel != 10]
return midi.translate.midiFileToStream(mf)
base_midi = open_midi(concat_path(sonic_path, "green-hill-zone.mid"), True)
base_midi
<music21.stream.Score 0xa27cfd828>
Debugging MIDI data
열린 미디 파일의 Instruments set을 확인해본다. 총 8개의 악기로 구성되어 있는데 Electoric Guitar 빼고는 unknown instrument로 표시되어 있는 상태이다. 곡마다 Instrument 이름이 제대로 매칭되는 경우도 있고 아닌 경우도 더러 있다.
def list_instruments(midi):
partStream = midi.parts.stream()
print("List of instruments found on MIDI file:")
for p in partStream:
aux = p
print (p.partName)
list_instruments(base_midi)
List of instruments found on MIDI file:
None
None
None
None
None
None
None
Electric Guitar
midi 파일의 note를 추출하고 그래프로 표현하는 부분이다. 그래프의 빨간선은 피아노 음계의 옥타브를 표현하고 옥타브 사이에 12음계(흰/검은 건반)가 있다고 생각하면 된다. 각 다른 악기들은 pitch note가 다른 색깔로 표현되어 있다.
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
def extract_notes(midi_part):
parent_element = []
ret = []
for nt in midi_part.flat.notes:
if isinstance(nt, note.Note):
ret.append(max(0.0, nt.pitch.ps))
parent_element.append(nt)
elif isinstance(nt, chord.Chord):
for pitch in nt.pitches:
ret.append(max(0.0, pitch.ps))
parent_element.append(nt)
return ret, parent_element
def print_parts_countour(midi):
fig = plt.figure(figsize=(12, 5))
ax = fig.add_subplot(1, 1, 1)
minPitch = pitch.Pitch('C10').ps
maxPitch = 0
xMax = 0
# Drawing notes.
for i in range(len(midi.parts)):
top = midi.parts[i].flat.notes
y, parent_element = extract_notes(top)
if (len(y) < 1): continue
x = [n.offset for n in parent_element]
ax.scatter(x, y, alpha=0.6, s=7)
aux = min(y)
if (aux < minPitch): minPitch = aux
aux = max(y)
if (aux > maxPitch): maxPitch = aux
aux = max(x)
if (aux > xMax): xMax = aux
for i in range(1, 10):
linePitch = pitch.Pitch('C{0}'.format(i)).ps
if (linePitch > minPitch and linePitch < maxPitch):
ax.add_line(mlines.Line2D([0, xMax], [linePitch, linePitch], color='red', alpha=0.1))
plt.ylabel("Note index (each octave has 12 notes)")
plt.xlabel("Number of quarter notes (beats)")
plt.title('Voices motion approximation, each color is a different instrument, red lines show each octave')
plt.show()
# Focusing only on 6 first measures to make it easier to understand.
print_parts_countour(base_midi.measures(0, 6))
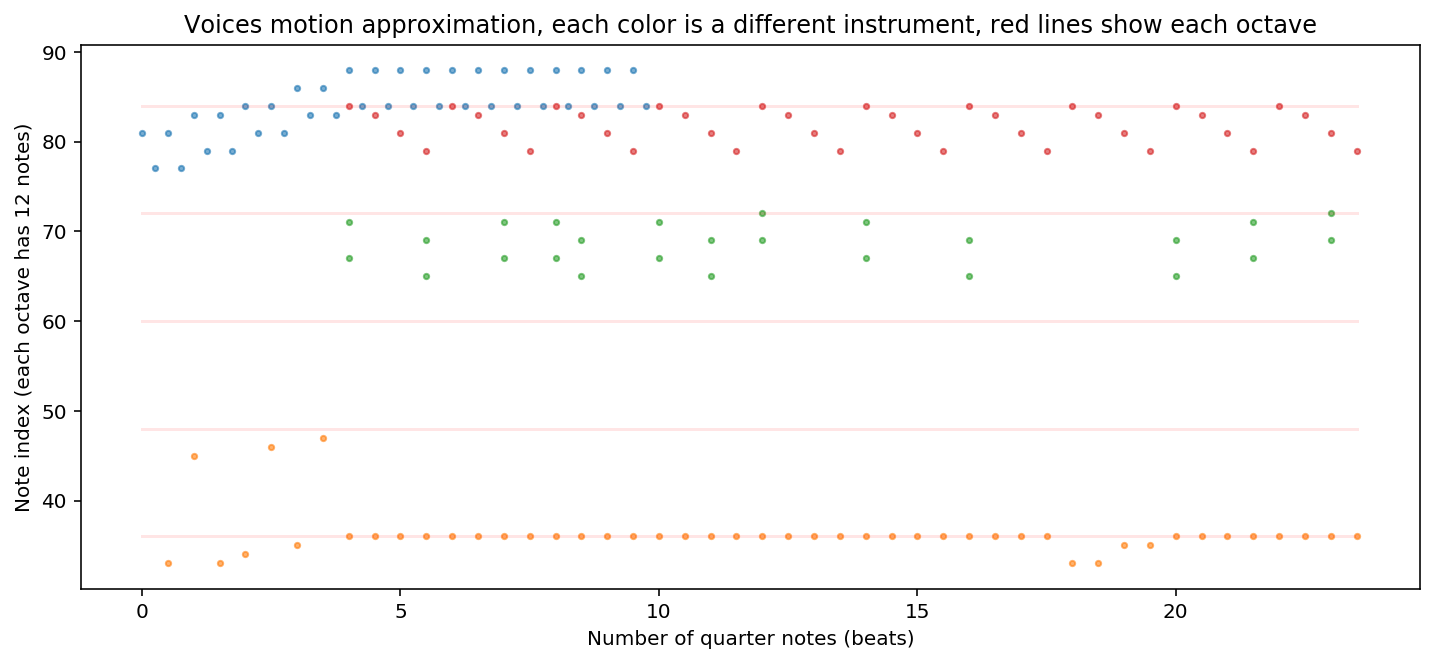
원곡은 다음 링크에서 확인 가능하다. (들어보니 제법 귀에 익은 음악이다) : original song
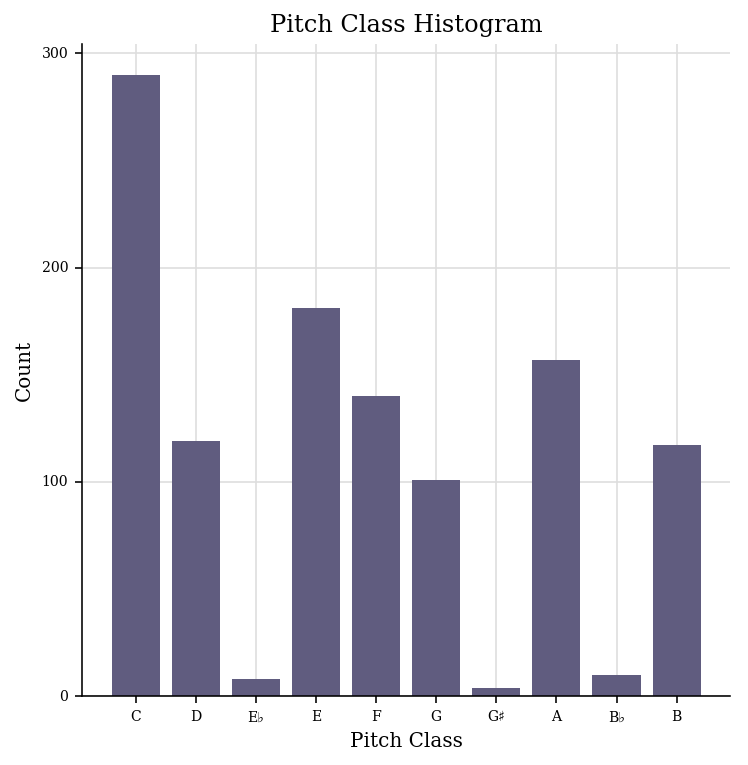
음악에 나오는 모든 악기, 모든 음정을 한 눈에 알아볼 수 있도록 표현하기는 어렵기 때문에 곡 전체에서 많이 쓰이는 음정(pitch)를 히스토그램으로 표현해본다. C, D, E, F, G, A, G가 많이 쓰이는 걸 보면 C-major 또는 A-minor Key 곡이라는 것을 알 수 있다.
base_midi.plot('histogram', 'pitchClass', 'count')
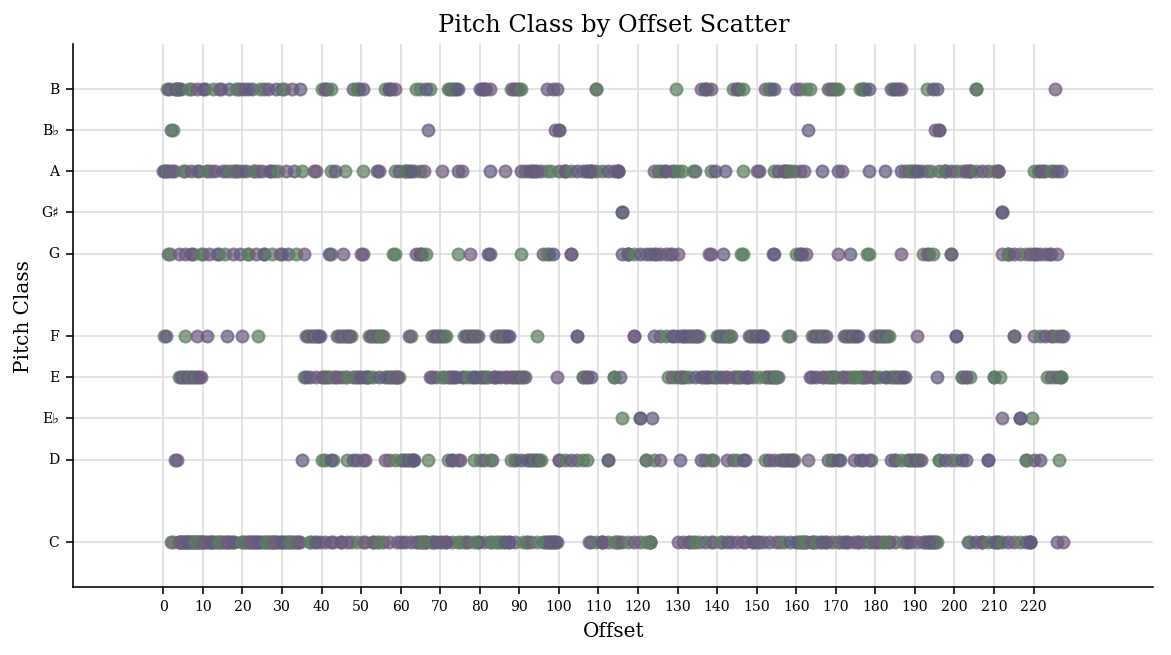
The scatter plot shows that the use of notes look consistent through time, so there are no key changes in this piece. 시간에 따른 pitch class 분포를 찍어보고 중간에 조성이 바뀌는 곡인지 아닌지 확인해본다.
base_midi.plot('scatter', 'offset', 'pitchClass')
이번에는 histogram이 아니라 라이브러리를 이용하여 곡의 박자와 조성을 읽어온다. (4/4박자, A minor Key)
timeSignature = base_midi.getTimeSignatures()[0]
music_analysis = base_midi.analyze('key')
print("Music time signature: {0}/{1}".format(timeSignature.beatCount, timeSignature.denominator))
print("Expected music key: {0}".format(music_analysis))
print("Music key confidence: {0}".format(music_analysis.correlationCoefficient))
print("Other music key alternatives:")
for analysis in music_analysis.alternateInterpretations:
if (analysis.correlationCoefficient > 0.5):
print(analysis)
Music time signature: 4/4
Expected music key: a minor
Music key confidence: 0.8770275812674332
Other music key alternatives:
C major
F major
G major
d minor
Harmonic Reduction
곡의 분석을 용이하게 하기 위해 music reduction을 수행한다. Music reduction이란 곡의 변형, 복잡한 리듬, block chord 등을 배제하여 곡의 복잡도를 줄이는 것이다. Citing the wikipedia explanation about this)
<music21.stream.Score 0xa291e6d30>
from music21 import stream
temp_midi_chords = open_midi(
concat_path(sonic_path, "green-hill-zone.mid"),
True).chordify()
temp_midi = stream.Score()
temp_midi.insert(0, temp_midi_chords)
# Printing merged tracks.
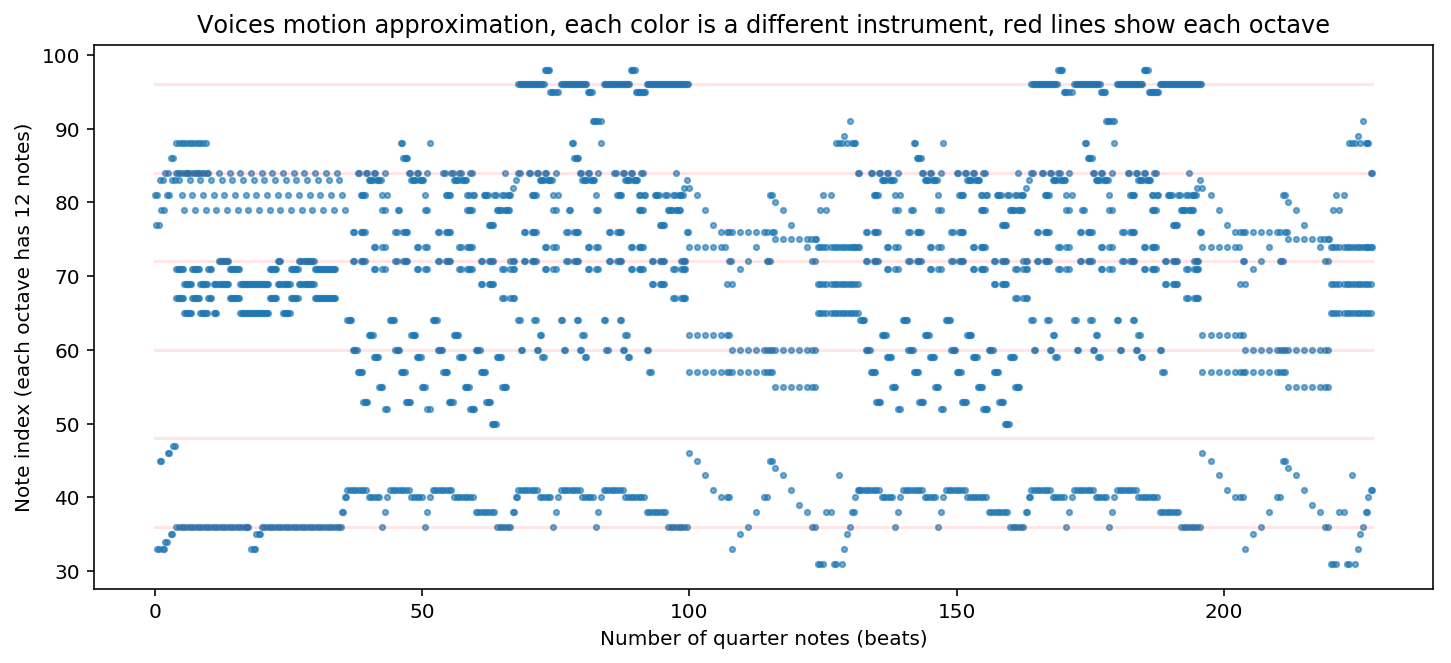
print_parts_countour(temp_midi)
# Dumping first measure notes
temp_midi_chords.measures(0, 1).show("text")
{0.0} <music21.stream.Measure 1 offset=0.0>
{0.0} <music21.instrument.Instrument ''>
{0.0} <music21.clef.TrebleClef>
{0.0} <music21.tempo.MetronomeMark Quarter=175.0>
{0.0} <music21.meter.TimeSignature 4/4>
{0.0} <music21.chord.Chord A5>
{0.25} <music21.chord.Chord F5>
{0.5} <music21.chord.Chord A1 A5>
{0.75} <music21.chord.Chord A1 F5>
{1.0} <music21.chord.Chord A2 B5>
{1.25} <music21.chord.Chord A2 G5>
{1.5} <music21.chord.Chord A1 B5>
{1.75} <music21.chord.Chord A1 G5>
{2.0} <music21.chord.Chord B-1 C6>
{2.25} <music21.chord.Chord B-1 A5>
{2.5} <music21.chord.Chord B-2 C6>
{2.75} <music21.chord.Chord B-2 A5>
{3.0} <music21.chord.Chord B1 D6>
{3.25} <music21.chord.Chord B1 B5>
{3.5} <music21.chord.Chord B2 D6>
{3.75} <music21.chord.Chord B2 B5>
각 악기의 음역대나 표현하고 있는 부분이 다르기 때문에 여러 코드가 섞여 있다. 따라서 각 마디에 해당하는 대표 코드를 표시하기 위해 제일 많이 쓰이는 4개의 음정을 추출하여 코드로 표현한다. 만약 대표 음정이 (E4, G4, C5, G5)로 정해지면 C-major 코드로 추정. (음정 옆의 숫자는 옥타브를 의미한다) First inversion
from music21 import roman
def note_count(measure, count_dict):
bass_note = None
for chord in measure.recurse().getElementsByClass('Chord'):
# All notes have the same length of its chord parent.
note_length = chord.quarterLength
for note in chord.pitches:
# If note is "C5", note.name is "C". We use "C5"
# style to be able to detect more precise inversions.
note_name = str(note)
if (bass_note is None or bass_note.ps > note.ps):
bass_note = note
if note_name in count_dict:
count_dict[note_name] += note_length
else:
count_dict[note_name] = note_length
return bass_note
def simplify_roman_name(roman_numeral):
# Chords can get nasty names as "bII#86#6#5",
# in this method we try to simplify names, even if it ends in
# a different chord to reduce the chord vocabulary and display
# chord function clearer.
ret = roman_numeral.romanNumeral
inversion_name = None
inversion = roman_numeral.inversion()
# Checking valid inversions.
if ((roman_numeral.isTriad() and inversion < 3) or
(inversion < 4 and
(roman_numeral.seventh is not None or roman_numeral.isSeventh()))):
inversion_name = roman_numeral.inversionName()
if (inversion_name is not None):
ret = ret + str(inversion_name)
elif (roman_numeral.isDominantSeventh()): ret = ret + "M7"
elif (roman_numeral.isDiminishedSeventh()): ret = ret + "o7"
return ret
def harmonic_reduction(midi_file):
ret = []
temp_midi = stream.Score()
temp_midi_chords = midi_file.chordify()
temp_midi.insert(0, temp_midi_chords)
music_key = temp_midi.analyze('key')
max_notes_per_chord = 4
for m in temp_midi_chords.measures(0, None): # None = get all measures.
if (type(m) != stream.Measure):
continue
# Here we count all notes length in each measure,
# get the most frequent ones and try to create a chord with them.
count_dict = dict()
bass_note = note_count(m, count_dict)
if (len(count_dict) < 1):
ret.append("-") # Empty measure
continue
sorted_items = sorted(count_dict.items(), key=lambda x:x[1])
sorted_notes = [item[0] for item in sorted_items[-max_notes_per_chord:]]
measure_chord = chord.Chord(sorted_notes)
# Convert the chord to the functional roman representation
# to make its information independent of the music key.
roman_numeral = roman.romanNumeralFromChord(measure_chord, music_key)
ret.append(simplify_roman_name(roman_numeral))
return ret
harmonic_reduction(base_midi)[0:10]
['ii42', 'III43', '-VI64', 'i42', '-VI', 'i65', 'i65', 'i42', 'III7', 'vi7']
위의 harmonic reduction을 보면 nonchord notes 가 존재하기 때문에 없어야할 코드도 보인다. 만약 Bach’s Prelude in C-major 처럼 코드 아르페지오로 연주되는 곡의 harmonic reduction 결과를 보면 minor error를 제외하고는 올바른 코드로 추려지는 것을 확인할 수 있다.
from music21 import corpus
bachChorale = corpus.parse('bach/bwv846')
harmonic_reduction(bachChorale)[0:11]
['I', 'ii42', 'vii53', 'I', 'vi6', 'ii42', 'V6', 'i42', 'vi7', 'II7', 'V']
MIDI Processing
지금까지 하나의 곡을 가지고 아래 작업을을 확인해보았다. 이제 대량의 미디 파일에 적용해보자.
- Open MIDI files;
- Manipulate tracks and notes;
- Plot music structure;
- Analyze MIDI basic features as time signatures;
- Analyze music elements as key signature and harmonic progressions.
import requests
from bs4 import BeautifulSoup
def get_file_name(link):
filename = link.split('/')[::-1][0]
return filename
def download_file(link, filename):
mid_file_request = requests.get(link, stream=True)
if (mid_file_request.status_code != 200):
raise Exception("Failed to download {0}".format(url))
with open(filename, 'wb+') as saveMidFile:
saveMidFile.write(mid_file_request.content)
def download_midi_files(url, output_path):
site_request = requests.get(url)
if (site_request.status_code != 200):
raise Exception("Failed to access {0}".format(url))
soup = BeautifulSoup(site_request.content, 'html.parser')
link_urls = soup.find_all('a')
for link in link_urls:
href = link['href']
if (href.endswith(".mid")):
file_name = get_file_name(href)
download_path = concat_path(output_path, file_name)
midi_request = download_file(href, download_path)
def start_midis_download(folder, url):
!mkdir $folder # It is fine if this command fails when the directory already exists.
download_midi_files(url, folder)
target_games = dict()
target_games["sonic1"] = "https://www.khinsider.com/midi/genesis/sonic-the-hedgehog"
target_games["sonic2"] = "https://www.khinsider.com/midi/genesis/sonic-the-hedgehog-2"
target_games["sonic3"] = "https://www.khinsider.com/midi/genesis/sonic-the-hedgehog-3"
target_games["sonicAndKnuckles"] = "https://www.khinsider.com/midi/genesis/sonic-and-knuckles"
for key, value in target_games.items():
file_path = concat_path(sonic_path, key)
start_midis_download(file_path, value)
450여개의 Sonic MIDI 데이터를 다운받는다. 이것은 original Sonic 음악을 fan이나 다른 사람들이 편곡하고 공유한 variation 버전이다. 이 곡들을 pandas Dataframe으로 변환하고 harmonic reduction 작업을 수행한다.
# from multiprocessing.dummy import Pool as ThreadPool # Use this when IO is the problem
from multiprocessing import Pool # Use this when CPU-intensive functions are the problem.
# Go get a coffee, this cell takes hours to run...
def process_single_file(midi_param):
try:
game_name = midi_param[0]
midi_path = midi_param[1]
midi_name = get_file_name(midi_path)
midi = open_midi(midi_path, True)
return (
midi.analyze('key'),
game_name,
harmonic_reduction(midi),
midi_name)
except Exception as e:
print("Error on {0}".format(midi_name))
print(e)
return None
def create_midi_dataframe(target_games):
key_signature_column = []
game_name_column = []
harmonic_reduction_column = []
midi_name_column = []
pool = Pool(8)
midi_params = []
for key, value in target_games.items():
folder_path = concat_path(sonic_path, key)
for midi_name in os.listdir(folder_path):
midi_params.append((key, concat_path(folder_path, midi_name)))
results = pool.map(process_single_file, midi_params)
for result in results:
if (result is None):
continue
key_signature_column.append(result[0])
game_name_column.append(result[1])
harmonic_reduction_column.append(result[2])
midi_name_column.append(result[3])
d = {'midi_name': midi_name_column,
'game_name': game_name_column,
'key_signature' : key_signature_column,
'harmonic_reduction': harmonic_reduction_column}
return pd.DataFrame(data=d)
sonic_df = create_midi_dataframe(target_games)
Error on final-boss-5-.mid
cannot place element with start/end 368.0/368.0 within any measures
Error on launch-base-electro-nation-mix-.mid
cannot place element with start/end 208.0/208.0 within any measures
Error on hydro-city-zone-act-2-speedy-remix-.mid
cannot place element <music21.tempo.MetronomeMark Quarter=125.0> with start/end 404.0/404.0 within any measures
Error on ice-cap-zone-good-future-remix-.mid
cannot place element with start/end 452.0/452.0 within any measures
Error on final-boss-2-.mid
cannot place element <music21.meter.TimeSignature 4/4> with start/end 268.0/268.0 within any measures
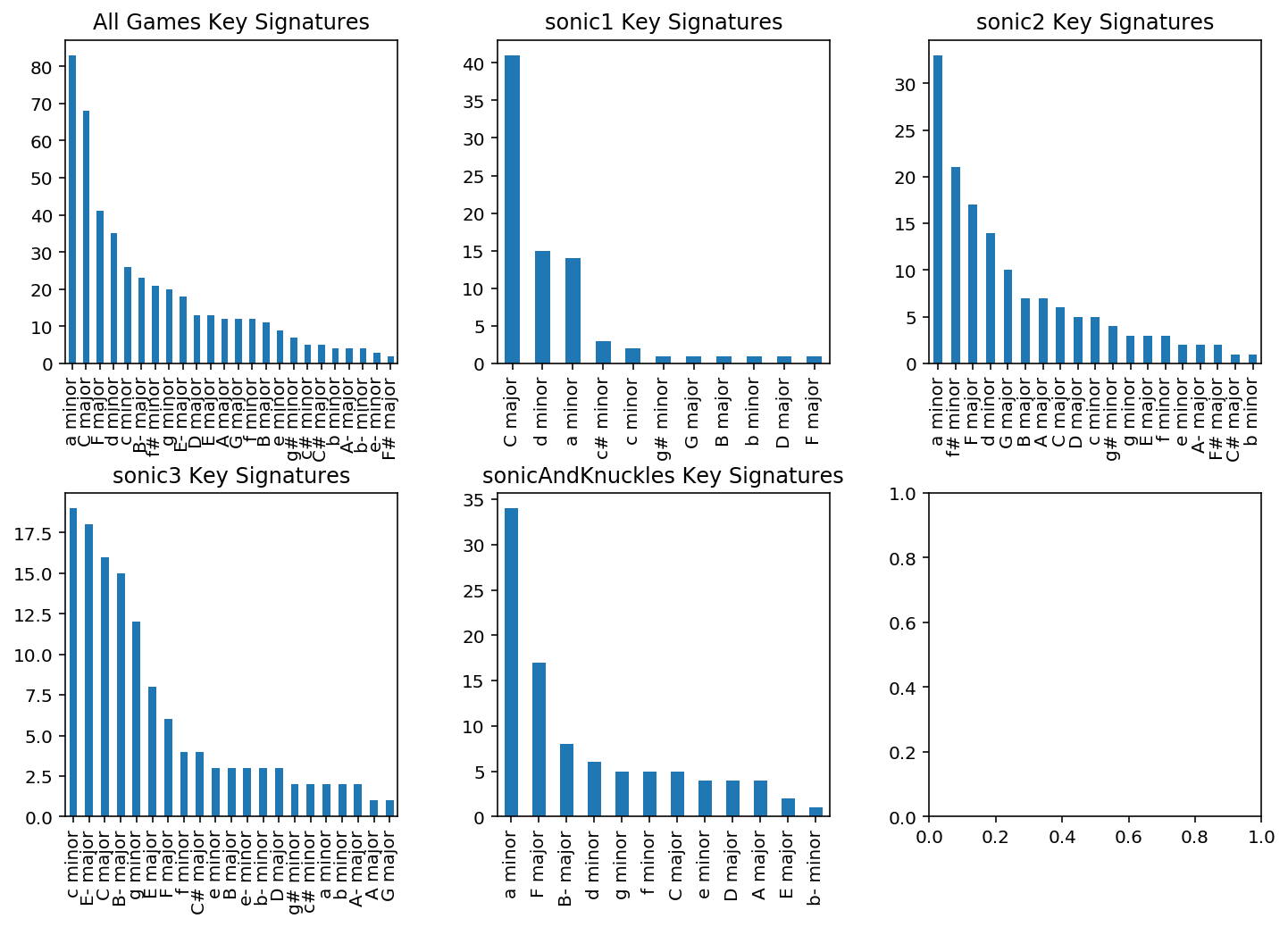
데이터셋 중 몇곡은 start/end 요소가 없어서 변환에 실패하기도 했지만 거의 모든 파일들의 변환이 완료되었다. 각 곡의 조성 히스토그램을 살펴보니 C-major / A-minor / F-major / D-minor가 제일 많이 쓰였다.
def key_hist(df, game_name, ax):
title = "All Games Key Signatures"
filtered_df = df
if (game_name is not None):
title = game_name + " Key Signatures"
filtered_df = df[df["game_name"] == game_name]
filtered_df["key_signature"].value_counts().plot(ax = ax, kind='bar', title = title)
fig, axes = plt.subplots(nrows=int(len(target_games)/3) + 1, ncols = 3, figsize=(12, 8))
fig.subplots_adjust(hspace=0.4, wspace=0.3)
key_hist(sonic_df, None, axes[0, 0])
i = 1
for key, value in target_games.items():
key_hist(sonic_df, key, axes[int(i/3), i%3])
i = i + 1
sonic_df.head()
| midi_name | game_name | key_signature | harmonic_reduction | |
|---|---|---|---|---|
| 0 | labyrinth-zone-2-yamaha-softsynth-.mid | sonic1 | C major | [iii, I53, iii, I53, iii, iv, ii, iv, iv42, I5... |
| 1 | final-zone.mid | sonic1 | a minor | [i, i53, i64, -VI7, v65, i53, i64, -VI53, -v6,... |
| 2 | spring-yard-zone-4-.mid | sonic1 | d minor | [IV, iii42, i, v7, i65, #iii42, i64, III42, i,... |
| 3 | labyrinth-zone-8-.mid | sonic1 | C major | [V6, I53, I64, I53, iii, IV, IV43, IV, ii, I, ... |
| 4 | labyrinth-zone-10-.mid | sonic1 | C major | [ii42, iii, vi42, iii, vi42, vi, ii42, vi, vi6... |
각 곡에 대한 harmonic sequence 결과를 얻었으니 이제 이를 string 데이터로 취급하여 word2vec을 활용하여 자연어처럼 다뤄보자.
# import modules & set up logging
import gensim, logging
# logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
model = gensim.models.Word2Vec(sonic_df["harmonic_reduction"], min_count=2, window=4)
raw dataset이 달라졌으므로 pre-trained된 word2vec을 쓰는 것이 아니라 hormonic_reduction string을 가지고 자체 Word2Vec 모델을 생성한다. 또한 단어간의 similarity를 확인하는 내장함수를 이용하여 각 코드의 similarity를 계산한다. 이렇게 되면 기존의 Word2Vec에서 사과-오렌지의 similarity 값이 높게 표현되는 것처럼 I - iii53 코드의 similarity의 유사성이 높게 측정되는 것을 확인할 수 있다. 이는 아래 링크의 대리코드 (한 화음대신 코드톤이 비슷한 다른 화음으로 대체할 수 있는 코드)의 결과와 비슷하다. Chord Substitutions
def get_related_chords(token, topn=3):
print("Similar chords with " + token)
for word, similarity in model.wv.most_similar(positive=[token], topn=topn):
print (word, round(similarity, 3))
def get_chord_similarity(chordA, chordB):
print("Similarity between {0} and {1}: {2}".format(
chordA, chordB, model.wv.similarity(chordA, chordB)))
print("List of chords found:")
print(model.wv.vocab.keys())
print("Number of chords considered by model: {0}".format(len(model.wv.vocab)))
get_related_chords('I')
get_related_chords('iv')
get_related_chords('V')
# The first one should be smaller since "i" and "ii" chord doesn't share notes,
# different from "IV" and "vi" which share 2 notes.
get_chord_similarity("I", "ii")
get_chord_similarity("IV", "vi")
# This one should be bigger because they are "enharmonic".
get_chord_similarity("-i", "vii")
List of chords found:
dict_keys(['iii', 'I53', 'iv', 'ii', 'iv42', 'v42', 'iii53', 'ii43', 'iii7', 'vi42', 'i', 'i53', 'i64', '-VI7', 'v65', '-VI53', '-v6', 'IV', 'iii42', 'v7', 'i65', '#iii42', 'III42', 'i43', 'V7', 'iv43', 'III65', '-', 'V6', 'I64', 'IV43', 'I', 'I65', 'vi', '-VII7', 'vi65', 'IV65', 'iii65', 'iii43', 'ii42', 'vi6', 'I6', 'IV42', 'VI53', 'ii53', 'IV53', '-II7', 'III7', 'vii42', '-VI', 'v53', 'vii', 'iv65', 'III', '-VI43', 'vi7', 'ii65', '-vii', 'I42', 'ii7', 'i6', '#vi65', '#vi', 'II64', 'v', 'II', '#vi42', 'iv7', '#i6', '#iii65', '#iv', 'III53', '-VII53', '-iii', '--vii42', '--vi6', '-vii7', '-vi', '-III53', '--vii43', '-vii42', '--vi', '-v', '-iii53', 'iii64', 'vi64', 'I7', 'i7', '-VII', '#v', 'I43', 'IV7', '-VII64', '-III', 'vii53', 'V53', 'V', 'VI', 'V65', 'ii64', '#i7', 'V43', '#v42', 'IV64', 'vi53', 'i42', '#vi6', '#vi43', '-VII42', '#vi7', 'V64', '-VI64', 'vii7', 'iv64', 'iii6', 'III43', '#iv7', '-iii6', '--vii', 'III6', '#v65', 'IV6', '-ii7', '-II42', '-II', '#vii7', '-v43', '-V42', '-V64', '-II53', 'vii43', 'v43', 'III64', 'VI64', '-VII6', '-VII65', '-iv', 'vi43', '#iv65', 'II42', 'II53', 'vii65', 'vii64', 'VI42', '#i43', '#iv6', '#iv53', 'V42', 'II43', '#i', '#i42', '-VI42', '#vii', 'ii6', '-i42', '-II6', '-VI6', '-II64', '-V', '#vii42', '#vii53', '#iv42', '-i', 'II7', '#ii7', 'v6', 'v64', '#vi53', '--vi53', '#iii', '#v43', '#ii', '-vii53', '-II65', '-iv7', '--iii', '-i6', '-i43', '--vii64', '##iii42', '##vi42', '##iii65', '##vi', '-I', '-I43', '-I7', '-I6', '-I53', '-ii', '-vi53', '--vi64', '--VI', '-v65', '-vii43', '-III64', '-iii42', '#i53', '-I42', 'II6', '-VI65', '#ii42', '-III6', '-III7', '-III65', '-III42', '-v42', '-I65', 'iv6', '#ii65', '#i64', '#i65', '--VI53', '-vi6', '--III53', '-iv43', '-vi42', '-i64', '--III64', '##vi65', '#ii43', '#iii7', 'vii6', 'iv53', '##vi7', 'VII53', 'VII', '#III', '##vi43', '-IV', 'VI6', '#iii43', '#III43', '--III', '#I64', '#I6', '--iii64', '#iii64', '-V7', '-iv42', '-vi43', '-vi65', '#vii64', '#vii6', '-vii6', '#iv64', '#vii43', '#ii53', '#iv43', '#vii65', '#v53'])
Number of chords considered by model: 250
Similar chords with I
iii53 0.984
iii7 0.983
I64 0.983
Similar chords with iv
ii 0.998
v65 0.989
III42 0.986
Similar chords with V
vi7 0.996
vi42 0.991
vi 0.99
Similarity between I and ii: 0.34506285190582275
Similarity between IV and vi: 0.7849031686782837
Similarity between -i and vii: 0.9656891822814941
또한 Word2Vec을 이용하여 단어에서 확장하여 문장의 유사성(Doc2Vec)을 확인할 수 있는 것처럼 harmonic reduction을 적용한 곡을 가지고 코드에서 확장하여 곡 자체의 유사성을 확인해볼 수 있다. 여기에서는 다음 링크의 예제코드를 활용하였다. code.
import pprint
def vectorize_harmony(model, harmonic_reduction):
# Gets the model vector values for each chord from the reduction.
word_vecs = []
for word in harmonic_reduction:
try:
vec = model[word]
word_vecs.append(vec)
except KeyError:
# Ignore, if the word doesn't exist in the vocabulary
pass
# Assuming that document vector is the mean of all the word vectors.
return np.mean(word_vecs, axis=0)
def cosine_similarity(vecA, vecB):
# Find the similarity between two vectors based on the dot product.
csim = np.dot(vecA, vecB) / (np.linalg.norm(vecA) * np.linalg.norm(vecB))
if np.isnan(np.sum(csim)):
return 0
return csim
def calculate_similarity_aux(df, model, source_name, target_names=[], threshold=0):
source_harmo = df[df["midi_name"] == source_name]["harmonic_reduction"].values[0]
source_vec = vectorize_harmony(model, source_harmo)
results = []
for name in target_names:
target_harmo = df[df["midi_name"] == name]["harmonic_reduction"].values[0]
if (len(target_harmo) == 0):
continue
target_vec = vectorize_harmony(model, target_harmo)
sim_score = cosine_similarity(source_vec, target_vec)
if sim_score > threshold:
results.append({
'score' : sim_score,
'name' : name
})
# Sort results by score in desc order
results.sort(key=lambda k : k['score'] , reverse=True)
return results
def calculate_similarity(df, model, source_name, target_prefix, threshold=0):
source_midi_names = df[df["midi_name"] == source_name]["midi_name"].values
if (len(source_midi_names) == 0):
print("Invalid source name")
return
source_midi_name = source_midi_names[0]
target_midi_names = df[df["midi_name"].str.startswith(target_prefix)]["midi_name"].values
if (len(target_midi_names) == 0):
print("Invalid target prefix")
return
return calculate_similarity_aux(df, model, source_midi_name, target_midi_names, threshold)
pp = pprint.PrettyPrinter(width=41, compact=True)
pp.pprint(calculate_similarity(sonic_df, model, "green-hill-zone.mid", "green")) # sonic1 x sonic1 music
pp.pprint(calculate_similarity(sonic_df, model, "green-hill-zone.mid", "emerald")) # sonic1 x sonic2 music
pp.pprint(calculate_similarity(sonic_df, model, "green-hill-zone.mid", "hydro")) # sonic1 x sonic3 music
pp.pprint(calculate_similarity(sonic_df, model, "green-hill-zone.mid", "sando")) # sonic1 x s&k music
[{'name': 'green-hill-zone.mid',
'score': 1.0},
{'name': 'green-hill-zone-11-.mid',
'score': 0.99936765},
{'name': 'green-hill-zone-4-.mid',
'score': 0.9993217},
{'name': 'green-hill-zone-yamaha-softsynth-.mid',
'score': 0.9982116},
{'name': 'green-hill-zone-12-.mid',
'score': 0.9952584},
{'name': 'green-hill-zone-9-.mid',
'score': 0.99341714},
{'name': 'green-hill-zone-8-.mid',
'score': 0.9913884},
{'name': 'green-hill-zone-5-v2-0-.mid',
'score': 0.9882838},
{'name': 'green-hill-zone-2-.mid',
'score': 0.98711455},
{'name': 'green-hill-zone-arranged-.mid',
'score': 0.9864178},
{'name': 'green-hill-zone-remix-.mid',
'score': 0.9844905},
{'name': 'green-hill-zone-3-.mid',
'score': 0.98035645},
{'name': 'green-hill-zone-legends-remix-.mid',
'score': 0.978596},
{'name': 'green-hill-zone-good-future-remix-.mid',
'score': 0.9738629},
{'name': 'green-hill-zone-remix-2-.mid',
'score': 0.9725929},
{'name': 'green-hill-zone-7-.mid',
'score': 0.9724128},
{'name': 'green-hill-zone-10-v2-0-.mid',
'score': 0.9624448},
{'name': 'green-hill-zone-6-.mid',
'score': 0.95736223}]
[{'name': 'emerald-hill-zone-2-player-2-.mid',
'score': 0.9852899},
{'name': 'emerald-hill-zone-2-player-gospel-choir-remix-xg-.mid',
'score': 0.95845896},
{'name': 'emerald-hill-zone-2-player.mid',
'score': 0.9530197},
{'name': 'emerald-hill-zone-2-player-3-.mid',
'score': 0.95154184},
{'name': 'emerald-hill-zone-2-player-remix-.mid',
'score': 0.94850504},
{'name': 'emerald-hill-zone-remix-.mid',
'score': 0.936994},
{'name': 'emerald-hill-zone-2-.mid',
'score': 0.936994},
{'name': 'emerald-hill-zone.mid',
'score': 0.9284813},
{'name': 'emerald-hill-zone-8-.mid',
'score': 0.9192649},
{'name': 'emerald-hill-zone-6-.mid',
'score': 0.91276616},
{'name': 'emerald-hill-zone-9-.mid',
'score': 0.90157956},
{'name': 'emerald-hill-zone-4-v3-0-.mid',
'score': 0.8729979},
{'name': 'emerald-hill-zone-7-.mid',
'score': 0.7914885},
{'name': 'emerald-hill-zone-5-.mid',
'score': 0.7888347},
{'name': 'emerald-hill-zone-3-.mid',
'score': 0.77974075}]
[{'name': 'hydro-city-zone-act-2-4-v2-0-.mid',
'score': 0.9756763},
{'name': 'hydro-city-zone-act-1.mid',
'score': 0.9675108},
{'name': 'hydro-city-zone-act-2.mid',
'score': 0.96133465},
{'name': 'hydro-city-zone-act-2-arranged-.mid',
'score': 0.96133465},
{'name': 'hydro-city-zone-act-1-3-.mid',
'score': 0.95509326},
{'name': 'hydro-city-zone-act-1-2-.mid',
'score': 0.95509326},
{'name': 'hydro-city-zone-act-2-3-.mid',
'score': 0.94458485},
{'name': 'hydro-city-zone-act-2-2-.mid',
'score': 0.8986722}]
[{'name': 'sandopolis-zone-act-2.mid',
'score': 0.9683789},
{'name': 'sandopolis-zone-waltrapa-remix-.mid',
'score': 0.96205324},
{'name': 'sandopolis-zone-act-2-2-.mid',
'score': 0.9575777},
{'name': 'sandopolis-zone-act-1-2-.mid',
'score': 0.9560668},
{'name': 'sandopolis-zone-act-1-3-.mid',
'score': 0.93191135},
{'name': 'sandopolis-zone-act-2-3-.mid',
'score': 0.9184958},
{'name': 'sandopolis-zone-act-1.mid',
'score': 0.91038704},
{'name': 'sandopolis-zone-act-1-4-.mid',
'score': 0.90284586}]
/Users/ykjang/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:7: DeprecationWarning: Call to deprecated `__getitem__` (Method will be removed in 4.0.0, use self.wv.__getitem__() instead).
import sys
결과를 보면 Green hill 음악이 다른 음악의 variation version 보다 유사성이 높은 것을 알 수 있다.
단상
사람이 듣기에 좋은 음악을 만들려면 여러가지 작곡법, 화성학 등이 필요한데 이러한 것들을 비전문가가 분석하고 이해하기에는 어려운 점이 있다. 음악의 베이스가 되는 코드 진행의 경우 자연어처럼 패턴이 있는 것을 이해하고 이를 word2vec 모델로 치환하여 활용한 것이 참 독특했다.
사실 음악 장르나 시대에 따라 코드 패턴이 어느 정도 정형화 되어 있기 때문에 이를 word처럼 인식해서 모델링 해보면 어떨까하며 찾아보다 알게된 글이였는데, 이미 시도해 본 분이 계셔서 기쁘기도 슬프기도… 했다. 왜 인간의 생각은 거의 비슷하고, 이미 그 생각을 실행한 사람은 내가 아닌 다른 사람인가..;;
수학처럼 딱 떨어지는 것은 아니지만 구조를 잡을 수 있는 체계가 있다는 것, 설명할 이유가 있다는 것, 순서가 중요하다는 것 등.. 음악과 언어는 많이 닮아있다. 자연어처리는 머신러닝/딥러닝 연구가 많이 되어왔지만 음악은 아직 그러지 못한 것 같아 자연어 처리에서 쓰이는 좋은 아이디어를 음악에 적용해보면 재미있는 연구가 많이 진행될 수 있을 것 같다.
댓글남기기